

We log anonymous usage statistics. Please read the privacy information for details.
Information-theoretic causal inference of lexical flow
Synopsis
This volume seeks to infer large phylogenetic networks from phonetically encoded lexical data and contribute in this way to the historical study of language varieties. The technical step that enables progress in this case is the use of causal inference algorithms. Sample sets of words from language varieties are preprocessed into automatically inferred cognate sets, and then modeled as information-theoretic variables based on an intuitive measure of cognate overlap. Causal inference is then applied to these variables in order to determine the existence and direction of influence among the varieties. The directed arcs in the resulting graph structures can be interpreted as reflecting the existence and directionality of lexical flow, a unified model which subsumes inheritance and borrowing as the two main ways of transmission that shape the basic lexicon of languages. A flow-based separation criterion and domain-specific directionality detection criteria are developed to make existing causal inference algorithms more robust against imperfect cognacy data, giving rise to two new algorithms. The Phylogenetic Lexical Flow Inference (PLFI) algorithm requires lexical features of proto-languages to be reconstructed in advance, but yields fully general phylogenetic networks, whereas the more complex Contact Lexical Flow Inference (CLFI) algorithm treats proto-languages as hidden common causes, and only returns hypotheses of historical contact situations between attested languages. The algorithms are evaluated both against a large lexical database of Northern Eurasia spanning many language families, and against simulated data generated by a new model of language contact that builds on the opening and closing of directional contact channels as primary evolutionary events. The algorithms are found to infer the existence of contacts very reliably, whereas the inference of directionality remains difficult. This currently limits the new algorithms to a role as exploratory tools for quickly detecting salient patterns in large lexical datasets, but it should soon be possible for the framework to be enhanced e.g. by confidence values for each directionality decision.
Statistics
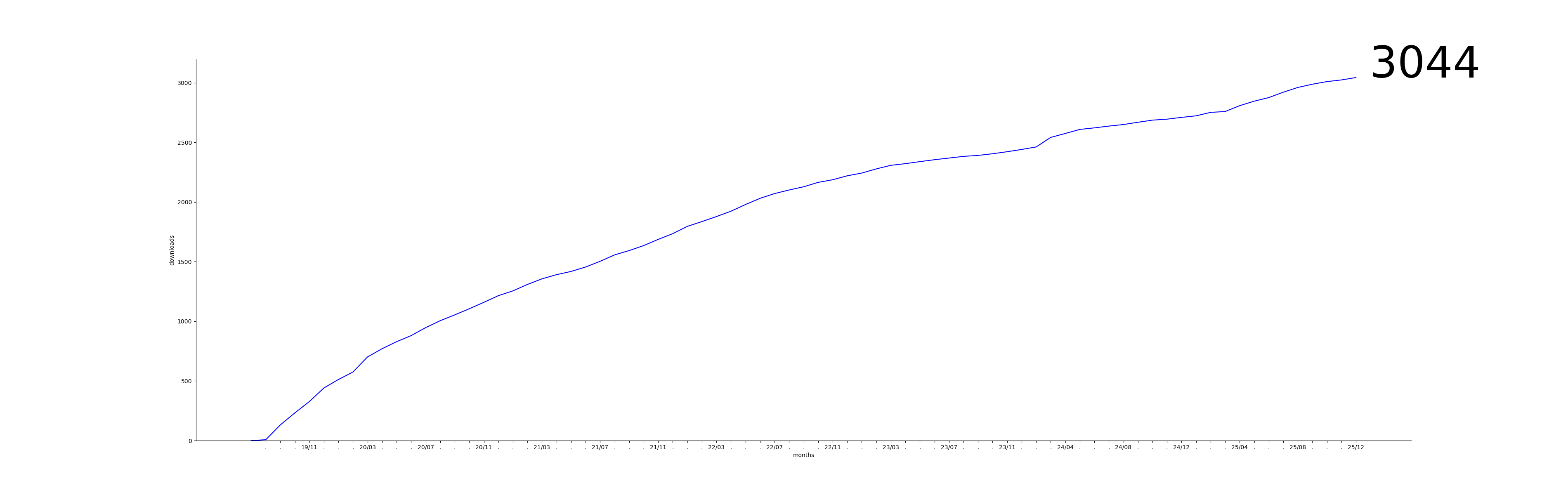

Downloads
Published
February 19, 2019
LaTeX source on
GitHub
Series
Print ISSN
2366-7818
Cite as
Dellert, Johannes. 2019. Information-theoretic causal inference of lexical flow. (Language Variation 4). Berlin: Language Science Press. DOI: 10.5281/zenodo.3247415
Copyright (c) 2019 Language Science Press
Details about the available publication format: PDF
PDF
ISBN-13 (15)
978-3-96110-143-6
Publication date (01)
2019-09-11
doi
10.5281/zenodo.3247415
Details about the available publication format: Hardcover
Hardcover
ISBN-13 (15)
978-3-96110-144-3
