

We log anonymous usage statistics. Please read the privacy information for details.
Referring expression generation in context: Combining linguistic and computational approaches
Synopsis
Reference production, often termed Referring Expression Generation (REG) in computational linguistics, encompasses two distinct tasks: (1) one-shot REG, and (2) REG-in-context. One-shot REG explores which properties of a referent offer a unique description of it. In contrast, REG-in-context asks which (anaphoric) referring expressions are optimal at various points in discourse.
This book offers a series of in-depth studies of the REG-in-context task. It thoroughly explores various aspects of the task such as corpus selection, computational methods, feature analysis, and evaluation techniques. The comparative study of different corpora highlights the pivotal role of corpus choice in REG-in-context research, emphasizing its influence on all subsequent model development steps. An experimental analysis of various feature-based machine learning models reveals that those with a concise set of linguistically-informed features can rival models with more features. Furthermore, this work highlights the importance of paragraph-related concepts, an area underexplored in Natural Language Generation (NLG). The book offers a thorough evaluation of different approaches to the REG-in-context task (rule-based, feature-based, and neural end-to-end), and demonstrates that well-crafted, non-neural models are capable of matching or surpassing the performance of neural REG-in-context models. In addition, the book delves into post-hoc experiments, aimed at improving the explainability of both neural and classical REG-in-context models. It also addresses other critical topics, such as the limitations of accuracy-based evaluation metrics and the essential role of human evaluation in NLG research.
These studies collectively advance our understanding of REG-in-context. They highlight the importance of selecting appropriate corpora and targeted features. They show the need for context-aware modeling and the value of a comprehensive approach to model evaluation and interpretation. This detailed analysis of REG-in-context paves the way for developing more sophisticated, linguistically-informed, and contextually appropriate NLG systems.
Statistics
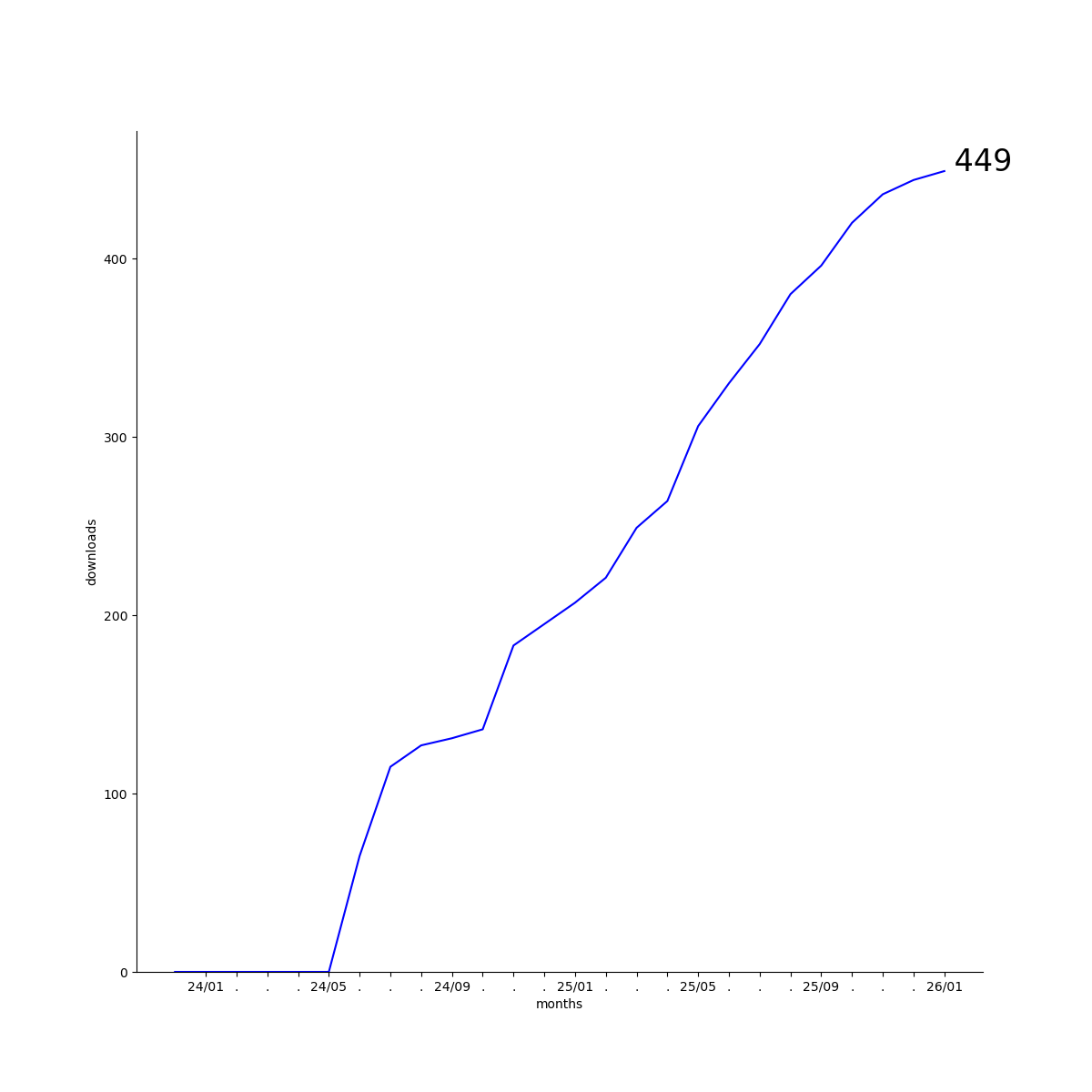

Downloads
Published
June 18, 2024
LaTeX source on
GitHub
Print ISSN
2567-3335
Cite as
Same, Fahime. 2024. Referring expression generation in context: Combining linguistic and computational approaches . (Topics at the Grammar-Discourse Interface 9). Berlin: Language Science Press. DOI: 10.5281/zenodo.11058114
Copyright (c) 2024 Fahime Same
Details about the available publication format: PDF
PDF
ISBN-13 (15)
978-3-96110-471-0
doi
10.5281/zenodo.11058114
Details about the available publication format: Hardcover
Hardcover
ISBN-13 (15)
978-3-98554-100-3
Physical Dimensions
180mm x 245mm
