

We log anonymous usage statistics. Please read the privacy information for details.
Corpus linguistics: A guide to the methodology
Synopsis
Corpora are widely used in linguistics, but not always wisely. This book attempts to frame corpus linguistics systematically as a variant of the observational method. The first part introduces the reader to the general methodological discussions surrounding corpus data as well as the practice of doing corpus linguistics, including issues such as the scientific research cycle, research design, extraction of corpus data and statistical evaluation. The second part consists of a number of case studies from the main areas of corpus linguistics (lexical associations, morphology, grammar, text and metaphor), surveying the range of issues studied in corpus linguistics while at the same time showing how they fit into the methodology outlined in the first part.
Statistics
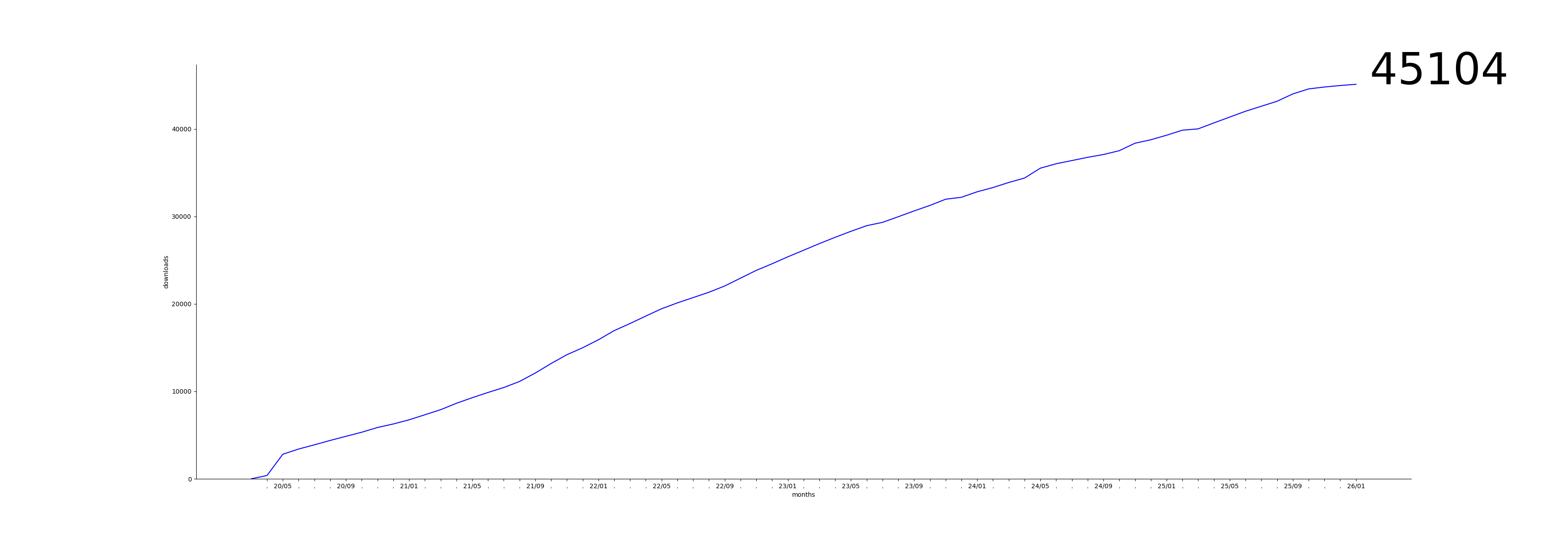

Downloads
Published
April 1, 2020
LaTeX source on
GitHub
Print ISSN
2364-6209
Cite as
Stefanowitsch, Anatol. 2020. Corpus linguistics: A guide to the methodology. (Textbooks in Language Sciences 7). Berlin: Language Science Press. DOI: 10.5281/zenodo.3735822
Copyright (c) 2020 Language Science Press
Details about the available publication format: PDF
PDF
ISBN-13 (15)
978-3-96110-224-2
doi
10.5281/zenodo.3735822
Details about the available publication format: Hardcover
Hardcover
ISBN-13 (15)
978-3-96110-225-9
