

We log anonymous usage statistics. Please read the privacy information for details.
Problem solving activities in post-editing and translation from scratch: A multi-method study
Synopsis
Companies and organisations are increasingly using machine translation to improve efficiency and cost-effectiveness, and then edit the machine translated output to create a fluent text that adheres to given text conventions. This procedure is known as post-editing.
Translation and post-editing can often be categorised as problem-solving activities. When the translation of a source text unit is not immediately obvious to the translator, or in other words, if there is a hurdle between the source item and the target item, the translation process can be considered problematic. Conversely, if there is no hurdle between the source and target texts, the translation process can be considered a task-solving activity and not a problem-solving activity.
This study investigates whether machine translated output influences problem-solving effort in internet research, syntax, and other problem indicators and whether the effort can be linked to expertise. A total of 24 translators (twelve professionals and twelve semi-professionals) produced translations from scratch from English into German, and (monolingually) post-edited machine translation output for this study. The study is part of the CRITT TPR-DB database. The translation and (monolingual) post-editing sessions were recorded with an eye-tracker and a keylogging program. The participants were all given the same six texts (two texts per task).
Different approaches were used to identify problematic translation units. First, internet research behaviour was considered as research is a distinct indicator of problematic translation units. Then, the focus was placed on syntactical structures in the MT output that do not adhere to the rules of the target language, as I assumed that they would cause problems in the (monolingual) post-editing tasks that would not occur in the translation from scratch task. Finally, problem indicators were identified via different parameters like Munit, which indicates how often the participants created and modified one translation unit, or the inefficiency (InEff) value of translation units, i.e. the number of produced and deleted tokens divided by the final length of the translation. Finally, the study highlights how these parameters can be used to identify problems in the translation process data using mere keylogging data.
Statistics
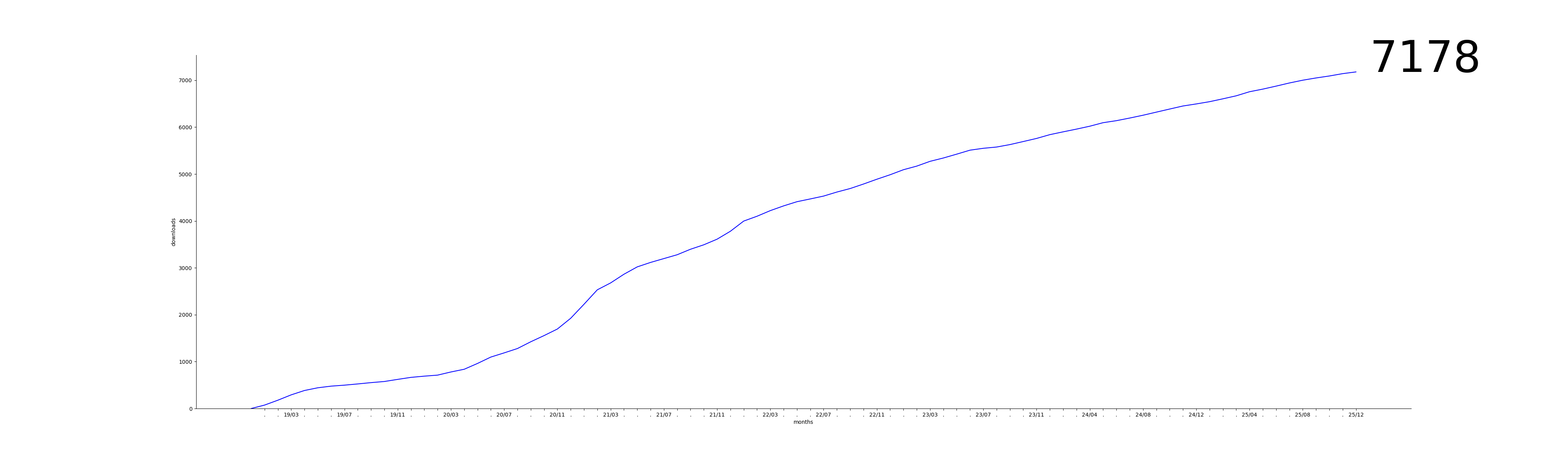

Downloads
Published
March 9, 2018
LaTeX source on
GitHub
Print ISSN
2364-8899
Cite as
Nitzke, Jean. 2018. Problem solving activities in post-editing and translation from scratch: A multi-method study. (Translation and Multilingual Natural Language Processing 12). Berlin: Language Science Press. DOI: 10.5281/zenodo.2546446
Copyright (c) 2018 Language Science Press
Details about the available publication format: PDF
PDF
ISBN-13 (15)
978-3-96110-131-3
Publication date (01)
2019-01-25
doi
10.5281/zenodo.2546446
Details about the available publication format: Hardcover
Hardcover
ISBN-13 (15)
978-3-96110-132-0
