

We log anonymous usage statistics. Please read the privacy information for details.
The Unicode cookbook for linguists: Managing writing systems using orthography profiles
Synopsis
This text is a practical guide for linguists, and programmers, who work with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together at the intersection between the Unicode Standard and the International Phonetic Alphabet. Although these standards are often met with frustration by users, they nevertheless provide language researchers and programmers with a consistent computational architecture needed to process, publish and analyze lexical data from the world's languages. Thus we bring to light common, but not always transparent, pitfalls which researchers face when working with Unicode and IPA. Having identified and overcome these pitfalls involved in making writing systems and character encodings syntactically and semantically interoperable (to the extent that they can be), we created a suite of open-source Python and R tools to work with languages using orthography profiles that describe author- or document-specific orthographic conventions. In this cookbook we describe a formal specification of orthography profiles and provide recipes using open source tools to show how users can segment text, analyze it, identify errors, and to transform it into different written forms for comparative linguistics research.
This book is a prime example of open publishing as envisioned by Language Science Press. It is open access, has accompanying open source software, has open peer review, versioning and so on. Read more in this blog post.
The book is continuously being improved. You can follow the development on https://github.com/unicode-cookbook/cookbook/releases/latest
Statistics
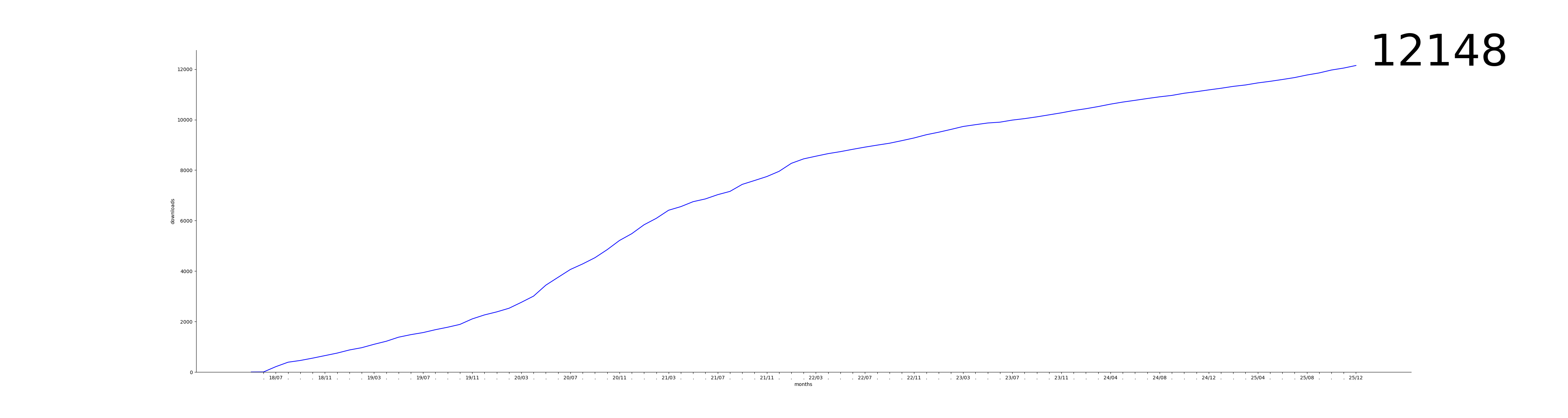

Downloads
Published
March 7, 2018
LaTeX source on
GitHub
Print ISSN
2364-8899
Cite as
Moran, Steven & Cysouw, Michael. 2018. The Unicode cookbook for linguists: Managing writing systems using orthography profiles. (Translation and Multilingual Natural Language Processing 10). Berlin: Language Science Press. DOI: 10.5281/zenodo.1296780
Copyright (c) 2018 Language Science Press
Details about the available publication format: PDF
PDF
ISBN-13 (15)
978-3-96110-090-3
Publication date (01)
2018-06-29
doi
10.5281/zenodo.1296780
Details about the available publication format: Hardcover
Hardcover
ISBN-13 (15)
978-3-96110-091-0
